

데이터 센터 고성능 컴퓨팅 솔루션
Accelerate your discoveries

AMD Instinct™ 가속기는 이 새로운 컴퓨팅 시대를 위해 처음부터 설계되었으며, HPC 및 AI 워크로드를 과급하여 새로운 발견을 추진합니다.
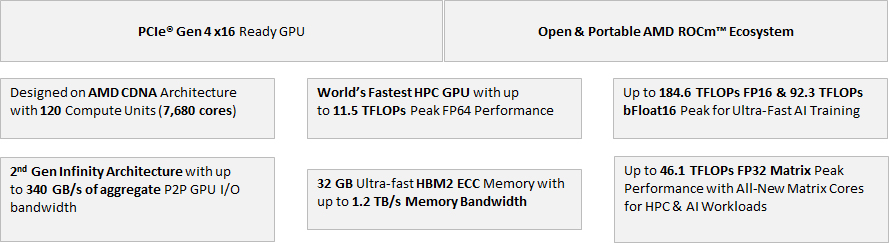
AMD CDNA 아키텍처로 구동되는 AMD Instinct™ MI100 가속기는 AMD의 이전 세대에 비해 HPC(FP32 matrix)의 경우 거의 3.5배 향상된 성능과 AI 워크로드(FP16)의 경우 거의 7배 향상된 컴퓨팅 및 연결성을 제공합니다.
수상 경력에 빛나는 AMD EPYC™ 프로세서 및 AMD Infinity Fabric™ 기술과 결합된 AMD Instinct™ GPU 기반 시스템은 과학자와 연구원에게 오늘 발견을 추진하고 미래의 엑사스케일에 대비하는 플랫폼을 제공합니다.
AMD Instinct™ 제품의 중심에는 Exascale 시대에 HPC와 AI의 융합을 위한 AMD CDNA 아키텍처가 있습니다.
처음부터 이전 세대보다 거의 1.8배의 FP64 성능 효율성을 제공하도록 설계된 컴퓨팅 코어와 HPC 및 AI 성능에서 거대한 도약을 제공하는 완전히 새로운 Matrix Cores 기술로 구동되는 AMD CDNA는 컴퓨팅 발견을 새로운 차원으로 끌어 올립니다.
Introducing AMD Instinct™ MI100 accelerator: First data center GPU to surpass the 10TF FP64 barrier.
HPC와 AI의 융합이 더해진 광대한 컴퓨팅 파워로 연구원들은 한 때는 해결이 불가능했던 어려운 과제들을 해결할 수 있습니다.
10TF FP64 장벽을 넘어선 최초의 데이터 센터 GPU

AMD Instinct™ MI100 가속기는 새로운 컴퓨팅 시대를 위해 철저히 제작된 세계에서 가장 빠른 HPC GPU입니다.
AMD CDNA 아키텍처 기반 MI100 가속기는 컴퓨팅 및 상호연결성 성능에서 상당한 비약을 제공해 이전 세대 AMD 가속기 대비 HPC에서 거의 3.5x의 부스트 (FP32 matrix) 및 AI에서 7x의 boost for AI (FP16) 처리율을 제공합니다.
"업계 최초의 개방형 소프트웨어 플랫폼인 AMD ROCm™이 지원하는 MI100 가속기는 고객이 AMD 솔루션에 고정되지 않는 개방형 플랫폼을 제공하여 개발자가 기존 GPU 코드를 향상시켜 어디에서나 실행할 수 있도록 합니다."
"AMD는 최고의 HPC 산업 솔루션 제공업체와 협력하여 데이터 센터를 위한 엔터프라이즈급 시스템 설계를 가능하게 합니다.
AMD EPYC™ 및 AMD Instinct™ 프로세서는 혁신적인 Infinity 아키텍처와 결합되어 기존 서버 병목 현상을 사실상 제거하여 실제 애플리케이션 배포에 최적화된 솔루션을 제공합니다."

"최대 11.5 TFLOP의 배정밀도(FP64) 이론상 최고 성능을 제공하는 AMD Instinct™ MI100 가속기는 HPC 애플리케이션을 위한 최고의 성능과 이전 세대 AMD 가속기에 비해 성능이 크게 향상되었습니다. MI100은 HPC 애플리케이션을 위해 최대 74% 세대 배정밀도 성능 향상을 제공합니다."

"완전히 새로운 매트릭스 코어 기술로 구동되는 AMD Instinct™ MI100 가속기는 AI 애플리케이션용 이전 세대 AMD 가속기에 비해 FP16 성능이 거의 7배 향상되었습니다. MI100은 AI 및 기계 학습 워크로드를 위한 혼합 정밀도 기능과 P2P GPU 연결을 크게 확장합니다."

Delivers ground-breaking technologies to fuel the convergence of HPC and AI in the era of Exascale.

With architecture, performance, and security leadership, our approach to processor design accelerates the pace of innovation so that you can break through years of data center stagnation.

The AMD ROCm™ open software platform brings a rich foundation to advanced computing by seamlessly integrating the CPU and GPU with the goal of solving real-world problems.

• Code development
• Code validation & certification
• Benchmark validation

• Compilers, libraries & management tools
• Workload containers
• Support forums
ROCm은 프로그래밍 언어에 독립적인 가속 컴퓨팅을 위한 최초의 오픈 소스 엑사스케일급 플랫폼입니다.
GPU 컴퓨팅에 선택의 철학, 미니멀리즘 및 모듈식 소프트웨어 개발을 제공합니다. 애플리케이션을 위한 도구와 언어 런타임을 자유롭게 선택하거나 개발할 수도 있습니다.
ROCm은 확장성을 위해 구축되었으며 다중 GPU 컴퓨팅을 지원하며 대규모 응용 프로그램, 컴파일러 및 언어 런타임 개발에 필요한 중요한 기능과 함께 풍부한 시스템 런타임을 제공합니다.
HPC용 ROCm 더 알아보기 머신 러닝(ML)을 위한 ROCm 더 알아보기

"Source: Oak Ridge National Laboratory: NAMD 2.14, STMV 1.06M atoms benchmark, 2x EPYC 7742 + MI100 vs 2x Power9 + V100 SXM, Cholla, Total Run measured. 2x EPYC 7742 + MI100 vs 2x
EPYC 7742 + V100, PIConGPU, Total Run measured. 2x EPYC 7742 + MI100 vs 2x EPYC 7742 + V100, GESTS, Total Run measured, 2x EPYC 7742 + MI100 vs 2x EPYC 7742 + V100"
Figure 6 – AMD Instinct™ MI100 GPU powering early exascale science at Oak Ridge
| AMD Instinct™ MI100 GPU Specifications | |
| GPU Architecture | CDNA |
|---|---|
| Compute Units | 120 |
| Peak Single Precision Matrix (FP32) Performance | 46.1 TFLOPs |
| Peak INT4 Performance | 184.6 TOPs |
| OS Support | Linux x86_64 |
| Lithography | TSMC 7nm FinFET |
| Peak Half Precision (FP16) Performance | 184.6 TFLOPs |
| Peak Single Precision (FP32) Performance | 23.1 TFLOPs |
| Peak INT8 Performance | 184.6 TOPs |
| Stream Processors | 7,680 |
| Peak Engine Clock | 1502 MHz |
| Peak Double Precision (FP64) Performance | 11.5 TFLOPs |
| Peak INT4 Performance | 184.6 TOPs |
| Peak INT8 Performance | 184.6 TOPs |
| Peak bfloat16 | 92.3 TFLOPs |
| External Power Connectors | 2x PCIe® 8-pin |
| Total Board Power (TBP) | 300W Peak |
| Dedicated Memory Size | 32 GB |
| Dedicated Memory Type | HBM2 |
| Memory Interface | 4096-bit |
| Memory Clock | 1.2 GHz |
| Peak Memory Bandwidth | Up to 1228.8 GB/s |
| Memory ECC Support | Yes (Full-Chip) |
| Bus Type | PCIe® 4.0 x16 / PCIe® 3.0 x16 |
| Cooling | Passive |
| Infinity Fabric™ Links | 3 |
| Software API Support | |
| OpenMP® | Yes |
| OpenCL™ | |
| HIP | |
| ROCm™ Open Ecosystem | |
| *GPU specifications may vary by partner configuration. Please refer to partner websites for GPU specifications. | |













