GPU가 탑재된 AI전용 서버에서 부터 Enterprise용 리눅스 Host OS, 다양한 딥러닝 프레임워크 사용을 위한 전용 컨테이너 플랫폼, 다양한 딥러닝 라이브러리 및 드라이버를 포함한 소프트웨어 스택 뿐 아니라 필요한 환경을 쉽게 구축할 수 있도록 돕는 프레임워크 예제 및 서비스가 완전히 통합된 토탈 서비스 플랫폼입니다.
독특하고 직관적인 GUI는 최적화 된 성능을 제공하기 위한 최고의 솔루션
슈퍼컴퓨터 토탈솔루션
GPU가 탑재된 AI전용 서버에서 부터 Enterprise용 리눅스 Host OS, 다양한 딥러닝 프레임워크 사용을 위한 전용 컨테이너 플랫폼, 다양한 딥러닝 라이브러리 및 드라이버를 포함한 소프트웨어 스택 뿐 아니라 필요한 환경을 쉽게 구축할 수 있도록 돕는 프레임워크 예제 및 서비스가 완전히 통합된 토탈 서비스 플랫폼입니다.
독특하고 직관적인 GUI는 최적화 된 성능을 제공하기 위한 최고의 솔루션

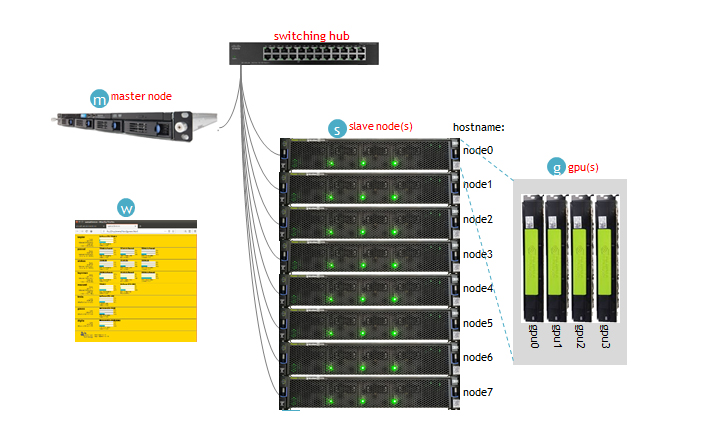
slave node(S)는 직접적인 연산을 담당하는 계산노드(computing node)를 의미하며 이들 각각에는 최소 하나 이상의 gpu가 장착되어 있고 (G) , master node (M) 는 이들 slave node들의 자원을 관리하고 가동률을 monitoring하기 위한 node(master node)를 의미합니다.
모든 gpu들의 상황정보는 1차적으로 각각의 slave node들에서 gpu의 정보가 취합된 후, 2차적으로 master node에서 전체적으로 취합되어져 web page형태로 (W) 와 같은 형식으로 표현되는 방식을 사용합니다.
이러한 일련의 과정은 매 수초 단위로 갱신되며, master node에서 web service가 이루어지고 있다면 이 web service를 이용할 수 있는 사용자들이 gpu의 정보를 이용할 수 있습니다.
따라서 이러한 monitoring을 위해서는 각각의 slave node에는 gpu의 정보를 수집하고 master node로 정보를 제공하기 위한 daemon의 설치가 필요하며, master node에는 각각의 slave node의 정보를 취합하여 web page를 작성하기 위한 프로그램의 설치가 필요합니다.(라이센스 발급)